I’ve been looking into temporary dynamic queues on midrange MQ. People tend to use these as a scratch queue which can be deleted when it has been finished with. Rather than use a shared reply queue, and get messages by msgid or correlid, you can just say get next message, as you know there will only be messages for your application instance on the queue.
The application team may save money by using a dynamic instead of a common replyTo queue, but you are likely to pay for it else where – including management time.
Using dynamic queues may be easy to program – but can have some serious implications.
Sometimes a dynamic queue is used because it saves the programmer about 5 minutes of coding by not specify nor testing gets specifying msgid or correlid.
One customer had a paranoid architect who did not want an application instance to have access to messages from another instance. With a well designed, coded, and reviewed application this should not occur – or use IBM MQ AMS to encrypt the messages.
I had a email from someone who said they are having problems with statistics on midrange because of the large number of dynamic queue – more of this later. I think they said they get statistics for 10 million dynamic queues a day, hence the question if they should change their applications.
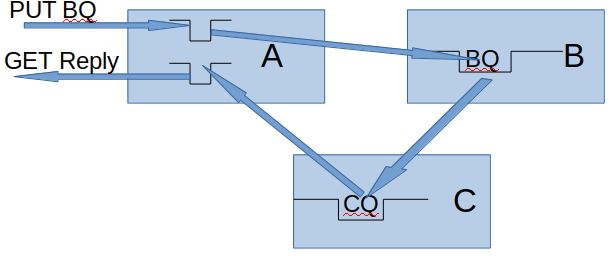
This temp dynamic queue can be used for
- a one-of: MQOPEN of a model queue to create a dynamic queue. Then MQPUT of request, the reply comes back to the dynamic queue, MQCLOSE of the reply queue, which deletes the queue.
- open the queue in the morning, use it all day when there is no work to do. The application ends, and deletes the queue.
You get the messages, close the queue, and the queue disappears – easy – what can go wrong?
I’ll cover
- the impact on the applications of using dynamic queues,
- the impact of systems management.
The impact of applications using dynamic queues
The documentation says The queues are deleted when the application that issued the MQOPEN call that created the queue closes the queue or terminates. … If the queue is in use at this time (by the creating, or another application), the queue is marked as being logically deleted, and is only physically deleted when closed by the last application using the queue.
For performance reasons, a receiver channel does not use MQPUT1 to put the messages to the queue, it does MQOPEN, MQPUT, MQPUT… as is many cases the same few queues are used. and MQOPEN, MQPUT, MQPUT is more efficient. After some time, if the queue has not been used the channel will close the queue.
The implications of this are that if the application is a one-of, the program started and finished in 1 second, a channel may keep hold of the queue. You think there is only one dynamic queue in use at any time, but if you have 1000 channels – there is potentially a lot of queues being only logically deleted and still around.
Conceptually the queue manager has to created the queue every time a dynamic queue is needed. In practice the queue manager has a pool of these which can be serially reused and so keep the costs down. This is fine for a small number of queues.
I did some totally unscientific measurement on my laptop to give a indication of the impact of using dynamic queues. The applications I used are completely non typical. The measurement give an indication and are meant to make you think about using dynamic queues rather than giving information you can use.
First measurement open the queues
Have a thread open a queue, 20,00 times. The application does 2000 opens, report statistics, wait 1 second, repeat.
| Queue type |
Average CPU per open |
Average Elapsed time uSeconds per open |
| Permanent |
First 2000 : 7
Last 2000 : 8 |
First 2000 : 64
Last 2000: 101 |
| Dynamic |
First 2000 : 8
Last 2000 : 8 |
First 2000 : 183
Last 2000: 303 |
The CPU usage looks similar, but the elapsed time increases when dynamic queues are used.
While the first program had its dynamic queues open, a second instance was run, the first 2000 took 290 microseconds, the last 2000 took 343 microsecond per open on average, so there is an increase in open time depending on the number of temp dynamic queues which are open. The increase is not just dependent of the number of queues opened per thread.
Second measurement – close the queues.
The queues were closed
- test 2A, in the order they were opened,
- test 2B, in reverse order of opening.
| Queue type |
Order |
Average CPU |
Average Elapsed time uSeconds |
| Permanent |
First opened, first closed |
First 2000 : 284 Last 2000 : 11 |
First 2000 : 1533
Last 2000: 83 |
| Permanent |
Last opened, first closed |
First 2000: 5
Last: 2000: 8 |
First 2000 : 58
Last 2000: 65 |
| Dynamic |
First opened, first closed |
First 2000 : 284 Last 2000 : 16 |
First 2000 : 1533
Last 2000: 783 |
| Dynamic |
Last opened, first closed |
First 2000: 8
Last: 2000: 8 |
First 2000: 295
Last: 2000: 736 |
When the queue is last-opened-first-closed this is much cheaper than first-opened-first- closed. It feels like there is a linear list of handles. It starts at the last opened, and scans backwards looking for the specific handle.
- An application should not have hundreds of queues open.
- If it does, the cost will depend, on where the handle is in the list – the “cheap end”, or the “expensive end”. You may have no control over this, so expect significant variation in the cost and elapsed time of performing the MQCLOSE on the queue.
- The dynamic queues took longer to close than the permanent queues
- In general it is quicker and uses less CPU time to open a permanent queue than using a dynamic queue. If you open and shut a queue 100 times a second this may be relevant. If you open and close them once a day, and keep them open all day, this is not so important.
Overwhelmed by statistics data.
All good production environment should be collecting statistics on queue usage. If the STATQ attribute is ON ( either for the queue, or for the queue manager) then a statistics record will be produced every STATINT seconds.
Each time I ran my test I had over 200 messages on SYSTEM.ADMIN.STATISTICS.QUEUE, and 20,000 records, one for each dynamic queue (100 record per statistics message).
For STATINT of 5 minutes, if I had opened the queues, and left them open, in a 10 hour day this would be 12 * 10 * 20,000 which is 2.4 million records. (If it reported the model queue name, instead of the generated name this would be just 120 records and would be so much more useful)!.
When I ran my program many times in the 5 minute interval I got many * 20,000 rows.
You take these records and store them in your statistics database, and instead of having one database row saying “at 0805 queue PAYROLL had 10000 MQPUTS”, you have 10,000 rows saying “At 0805 Queue AMQ.5CF22BF6214…. had one MQPUT”. As you keep your data for at least 13 months (so you can look back at last year’s peak periods), you have a lot of data and wasted space.
What you can do.
- Turn off stats collection for these dynamic queues – not very helpful.
- Post process the data and aggregate all of the dynamic queues for a period into one record (select (sum(puts),….) where qname like ‘AMQ%’….) – and then delete the individual records. Extra work which could be avoided if you did not use dynamic queues.
- Use a model queue name for each business application so you get MOBILE.5CF22BF62144A7A4, and CreditCheck.5CF22BF62144A7A4 instead of AMQ.5CF22BF62144A7A4 to make it easier to see where the queues are used.
- Change the applications to use a shared reply queue. This may be the hardest one to do.
- Ensure the applications get their message by MSGID or CORRELID, and not just get next.
- Use a common reply queue names to provide isolation – such as MOBILE.REPLY and CREDITCHECK.REPLY.
- You may have to implement best practices of cleaning up old messages. If a dynamic queue was closed any messages on the queue would be deleted. As you are not deleting the common queue – you need to clean these up yourself. This can occur when an application timed out and then the reply arrived.
In summary
The applications team may have saved some money by using a dynamic queue instead of a shared reply queue – but you will spend much more money, on CPU, disk space for database tables. Then of course there is the management time spent discussing why the reporting of dynamic queue usage is not so useful.
 Once I Once I got it working the definitions were simple.
Once I Once I got it working the definitions were simple.