I found using Zowe explorer was not intuitive, and I had a lot of help to get started.
This blog post explains how to submit JCL, look at the output etc.
Depending on how you are doing authentication you may get prompted for userid, password or both. I use certificate logon, so do not get prompted.
I have a PDS with C code, and a PDS containing the JCL to compile, bind and run the program. I wanted to edit the C source, submit the JCL, and look at the output.
Editing a C file
- Open Zowe explorer (the Z in a diamond icon)
- Under data sets, select a profile. You may be prompted to logon.
- Select the search icon (magnifying glass)
- Select an existing filter, or create a new one, (for example COLIN.C.Z* )
- Press enter. This will list the data sets matching the search criteria
- Single click the data set to display the members
- Single click the member name to edit it
- Use Ctrl+S to save your changes.
Editing the JCL file
- Follow the steps above to open the JCL member
- Right click and select Submit as JCL
- This will create a pop up, at the bottom right of the screen with the job number.
- You can click the job number, and this will open the job under JOBS and the profile on the left hand side. If you have a spool job filter, (to display your spool files) you may not want to click on the pop up job id.
- Single click the job (under JOBS) to display the content of the spool data sets
Display your usual list of jobs
If you clicked on the pop up window giving the submitted job name, it creates a temporary filter under the JOBS profile.
To reset this back to normal, click on the profile’s search icon, select the filter you want, and select Select this query. (This is too many clicks for me!)
Edit the C file again
You can now go to the C source tab and continue editing your program.
To speed things up
Create/use a keyboard short cut
To jump between the editor windows. Ctrl+Tab, Tab etc to the window. Ctrl+shift+tab to tab backwards.
You can use keyboard short cuts for some of the above. I wanted to create a shortcut to submit JCL.
Ctrl+K Ctrl+S gives the current keyboard short cuts.
Type Ctrl+J in the search window. It gave me

Ctrl+J is in use, so I’ll use Ctrl+Alt+J
Type submit JCL into the search window. This gave me
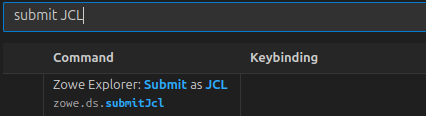
So I can see it is not bound to a key.
Click on the item, and on the + sign which appears. A window pops up. Use the key combination, and press enter.
Use favourites
For data sets you often use, you can click on them and add to favourites, so they are always there
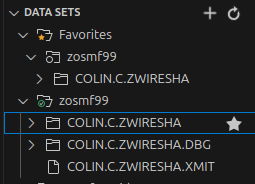
To have favourites spool job filters when you are looking at the spool.
- Select the spool filter (and display any output)
- Right click on the profile, and select Add to favourites
- The filter will then appear in the Favourites section
If you submit a job, click on the popup window jobid, it will display it in the JOBS, under the active profile. You can get back to your usual spool filter settings, by going to the favourites.
Thanks
With thanks to Joshua Waters for all of his patience in helping me.
